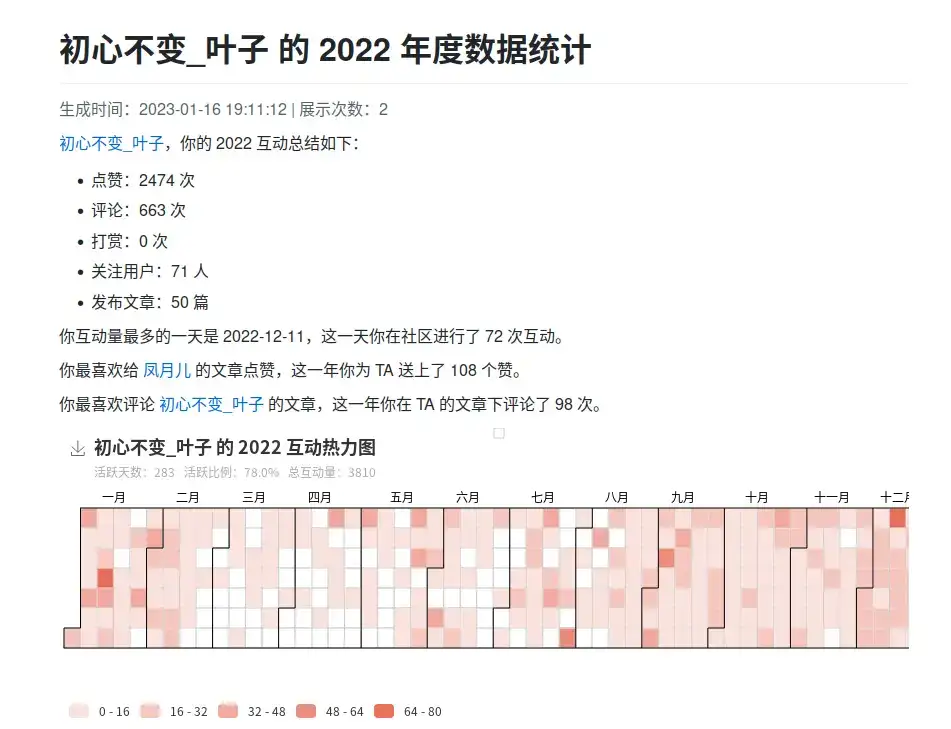
数据洪流时代的生命线:基于Spark+Hbase的亿级流量分析实战解析
2023-12-11 09:20:00
数据洪流时代的救星:Spark + Hbase 构建高效 ETL 解决方案
引言:数据,企业宝藏中的洞察金矿
在当今数字化时代,数据已成为企业和组织的宝贵资产,蕴藏着无限的洞察和价值。然而,面对不断增长的数据洪流,如何有效地处理和分析数据,以便及时获取洞察并做出明智的决策,成为一项重大挑战。
拥抱大数据:Spark 和 Hbase 的威力
为了解决这一难题,企业和组织纷纷采用大数据技术来构建数据分析系统。其中,Spark 和 Hbase 是两个备受欢迎的大数据组件,它们分别用于快速处理海量数据和存储海量数据。
Spark 简介:海量数据处理利器
Spark 是一款开源大数据处理框架,以其惊人的速度和分布式计算能力著称。它采用内存计算技术,将数据存储在内存中进行处理,大大提高了处理速度。此外,Spark 还支持分布式计算,可以将任务分配给多个节点同时执行,进一步提升了处理效率。
Hbase 简介:海量数据存储巨头
Hbase 是一款开源分布式数据库,专为存储海量数据而设计。它采用列式存储技术,可以快速查询数据。此外,Hbase 还支持高并发,能够同时处理大量的请求,轻松应对数据洪流的挑战。
Spark + Hbase:协同构建 ETL 解决方案
将 Spark 和 Hbase 的优势结合起来,我们可以构建一个高性能的 ETL(Extract-Transform-Load)解决方案,满足数据流快速增长的需求。ETL 是数据仓库建设中的一个关键环节,负责将数据从不同来源提取、清洗、转换并装载到数据仓库中,为数据分析和决策提供统一的数据基础。
ETL 解决方案的架构
我们的 ETL 解决方案采用如下架构:
[Image of ETL architecture]
数据提取:从各种来源收集数据
数据提取是 ETL 的第一步,也是至关重要的一步。我们需要将数据从不同的来源中提取出来,这些来源可能包括数据库、日志文件、传感器等。
Spark 提供了丰富的连接器,可轻松连接到各种数据源。例如,我们可以使用 Spark SQL 连接数据库,使用 Spark Streaming 连接日志文件,使用 Spark MLlib 连接传感器等。
数据清洗:清除错误和不一致之处
数据清洗是 ETL 的第二步,同样非常重要。它负责清除数据中的错误和不一致之处,以确保数据质量。数据清洗包括以下步骤:
- 数据验证:检查数据是否符合预期的格式和范围。
- 数据转换:将数据转换为统一的格式。
- 数据去重:删除重复的数据。
- 数据修复:修复错误的数据。
Spark 提供了强大的数据清洗工具,帮助我们轻松完成数据清洗任务。例如,我们可以使用 Spark SQL 进行数据验证和转换,使用 Spark Streaming 进行数据去重,使用 Spark MLlib 进行数据修复等。
数据转换:调整数据以适合数据仓库
数据转换是 ETL 的第三步,负责将数据转换为适合数据仓库的格式。它包括以下步骤:
- 数据聚合:对数据进行聚合操作,如求和、求平均值、求最大值等。
- 数据分组:将数据按照特定字段分组。
- 数据排序:将数据按照特定字段排序。
Spark 提供了多样化的数据转换工具,使我们能够轻松完成数据转换任务。例如,我们可以使用 Spark SQL 进行数据聚合和分组,使用 Spark Streaming 进行数据排序等。
数据装载:将数据导入数据仓库
数据装载是 ETL 的第四步,也是最后一步。它负责将数据装载到数据仓库中,以便进行数据分析和决策。数据仓库可以是关系型数据库、NoSQL 数据库或数据湖等。
Spark 提供了多种数据装载器,可将数据方便地装载到不同类型的数据仓库中。例如,我们可以使用 Spark SQL 将数据装载到关系型数据库,使用 Spark Streaming 将数据装载到 NoSQL 数据库,使用 Spark MLlib 将数据装载到数据湖等。
代码示例:Spark + Hbase ETL 管道
以下是使用 Spark 和 Hbase 构建 ETL 管道的代码示例:
// 定义从数据库中提取数据的 Spark SQL 查询
val df = spark.read.jdbc(...)
// 使用 Spark SQL 对数据进行转换
val transformedDF = df.select(...)
// 将转换后的数据写入 Hbase
transformedDF.write.format("org.apache.hadoop.hbase.spark").saveAsTable(...)
结论:应对数据洪流的利器
通过结合 Spark 和 Hbase 的强大功能,我们可以构建一个高性能的 ETL 解决方案,满足数据流快速增长的需求。该解决方案可帮助企业和组织从海量数据中挖掘洞察,从而做出更明智的决策,推动业务增长。
常见问题解答
- 为什么需要使用 Spark 和 Hbase 构建 ETL 解决方案?
Spark 擅长快速处理海量数据,而 Hbase 擅长存储海量数据。将它们结合起来,我们可以构建一个高性能的 ETL 解决方案,满足数据洪流的需求。
- Spark + Hbase ETL 解决方案有哪些好处?
- 高性能:Spark 的分布式计算能力和 Hbase 的高并发性确保了高性能的数据处理。
- 可扩展性:该解决方案可以轻松扩展,以处理不断增长的数据量。
- 容错性:Spark 和 Hbase 都是高度容错的,可以防止数据丢失。
- 如何使用 Spark + Hbase 构建 ETL 解决方案?
您可以按照本文中概述的步骤构建 ETL 解决方案,或参考代码示例。
- Spark + Hbase ETL 解决方案有哪些局限性?
该解决方案可能不适用于所有数据集,尤其是不适合处理小数据集或结构化程度低的数据集。
- 有哪些替代方案可以使用?
还有其他大数据组件可用于构建 ETL 解决方案,例如 Apache Flink 和 Apache Hive。