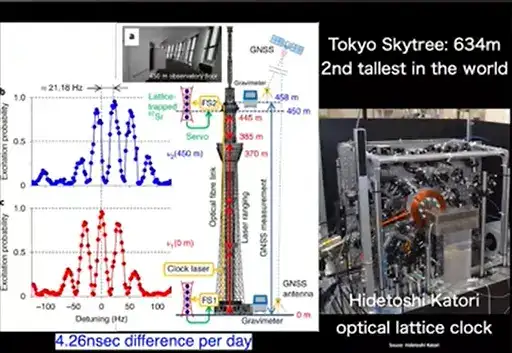
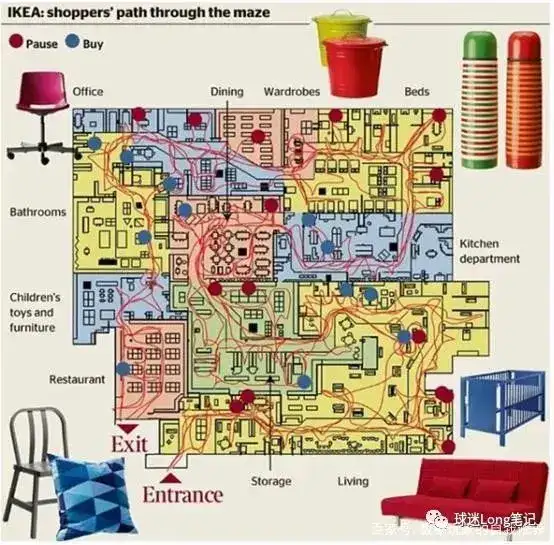
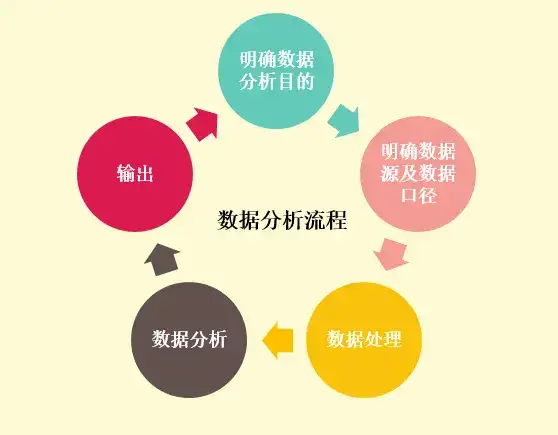
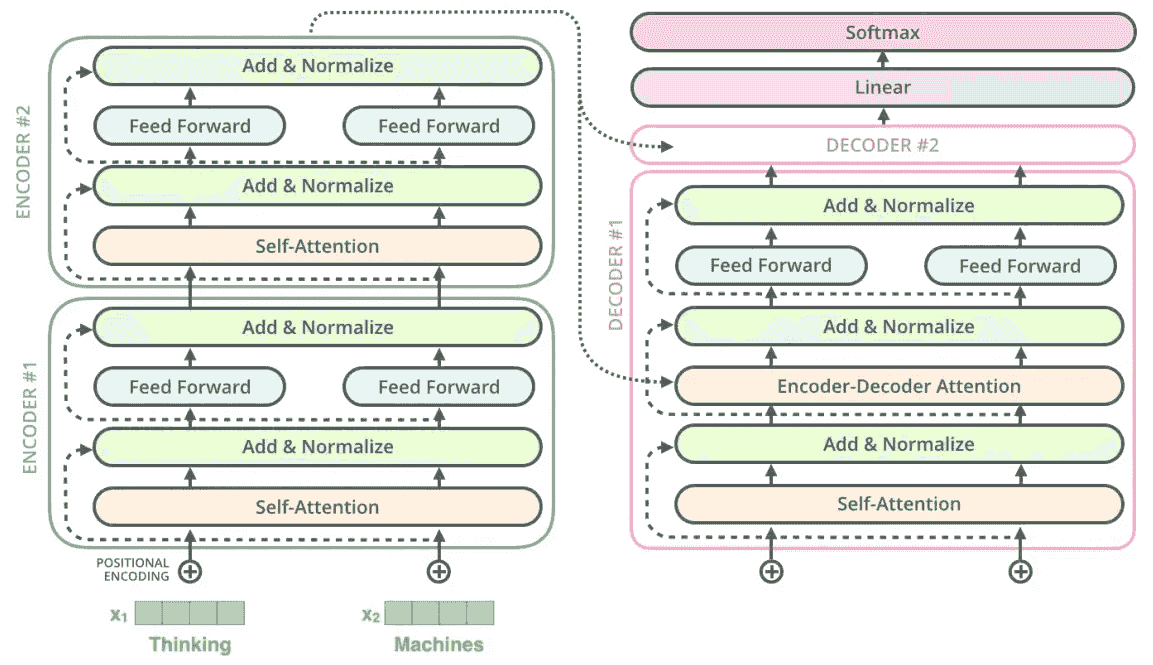
梯度下降算法:优化之路的领航者
2023-10-09 10:29:03
揭秘梯度下降:机器学习中的优化之锚
在机器学习浩瀚的世界中,优化算法犹如一盏明灯,引领着我们通往模型参数的最佳之路。其中,梯度下降算法历经岁月洗礼,始终稳坐优化无约束问题的头把交椅。它的老搭档最小二乘法也毫不逊色,但在今天,我们聚焦于梯度下降算法,揭开它的优雅面纱。
梯度下降的本质
梯度下降算法的精髓在于它迭代式地沿着负梯度方向更新模型参数,目标直指找到目标函数的极值(最大值或最小值)。在每次迭代中,算法都会根据以下公式更新参数:
参数 = 参数 - 学习率 * 梯度
其中,学习率是控制算法步长的超参数。梯度表示目标函数相对于参数的导数,指明了函数变化最快的方向。通过沿着负梯度方向更新参数,算法逐步逼近极值。
梯度下降的优势
梯度下降算法凭借以下优势傲视群雄:
- 简单易懂: 算法原理清晰明了,容易理解和实现。
- 高效稳定: 对于凸目标函数,梯度下降算法能够收敛到全局最优解。
- 广泛适用: 算法适用于各种机器学习模型的优化,如线性回归、逻辑回归和神经网络。
梯度下降的局限
尽管优点颇多,梯度下降算法也并非完美无瑕,其局限性主要体现在以下方面:
- 收敛速度: 算法收敛速度取决于目标函数的性质和学习率的选择。
- 局部极小值: 对于非凸目标函数,算法可能收敛到局部极小值而不是全局最优解。
- 学习率选择: 学习率的选择至关重要,过大可能导致算法不稳定,过小则会导致收敛速度缓慢。
学习率的重要性
在梯度下降算法中,学习率扮演着不可或缺的角色。它决定了算法在负梯度方向上的步长大小。学习率过大,算法可能越过极值,导致不稳定。学习率过小,算法收敛速度会非常缓慢。
对于不同的目标函数和优化问题,需要根据实际情况选择合适的学习率。一些算法(如Adam和RMSprop)通过自适应调整学习率来提升算法性能。
梯度下降在机器学习中的应用
梯度下降算法在机器学习领域有着广泛的应用,包括:
- 参数估计: 用于估计线性回归、逻辑回归和神经网络等模型的参数。
- 超参数优化: 用于优化超参数(如正则化系数),以提高模型性能。
- 神经网络训练: 用于训练深度神经网络,以执行图像识别、自然语言处理等任务。
梯度下降的扩展
为了克服梯度下降算法的局限性,研究人员提出了各种扩展算法,包括:
- 动量法: 加入动量项,加速收敛。
- RMSprop: 自适应调整学习率,提高稳定性。
- Adam: 结合动量法和RMSprop的优点,是一种更强大的优化算法。
结语
梯度下降算法是机器学习中一款功能强大的优化工具,在解决无约束优化问题方面有着不可替代的作用。尽管存在局限性,但通过精心设计和扩展,梯度下降算法仍然是优化模型参数和解决现实世界问题的首选。
常见问题解答
1. 什么是目标函数?
目标函数是需要最小化或最大化的函数,它衡量模型的性能。
2. 什么是导数?
导数是函数相对于输入变量变化率的度量,它表示函数变化最快的方向。
3. 如何选择合适的学习率?
学习率的选择取决于目标函数的性质和优化问题的具体情况。通常需要通过试验不同的值来找到最佳学习率。
4. 为什么梯度下降算法可能收敛到局部极小值?
对于非凸目标函数,梯度下降算法可能陷入局部极小值,而不是找到全局最优解。
5. 如何加速梯度下降算法的收敛速度?
可以使用动量法、RMSprop或Adam等扩展算法来加速梯度下降算法的收敛速度。