Hashbrown 和哈希表内的奥秘
2023-11-24 16:55:46
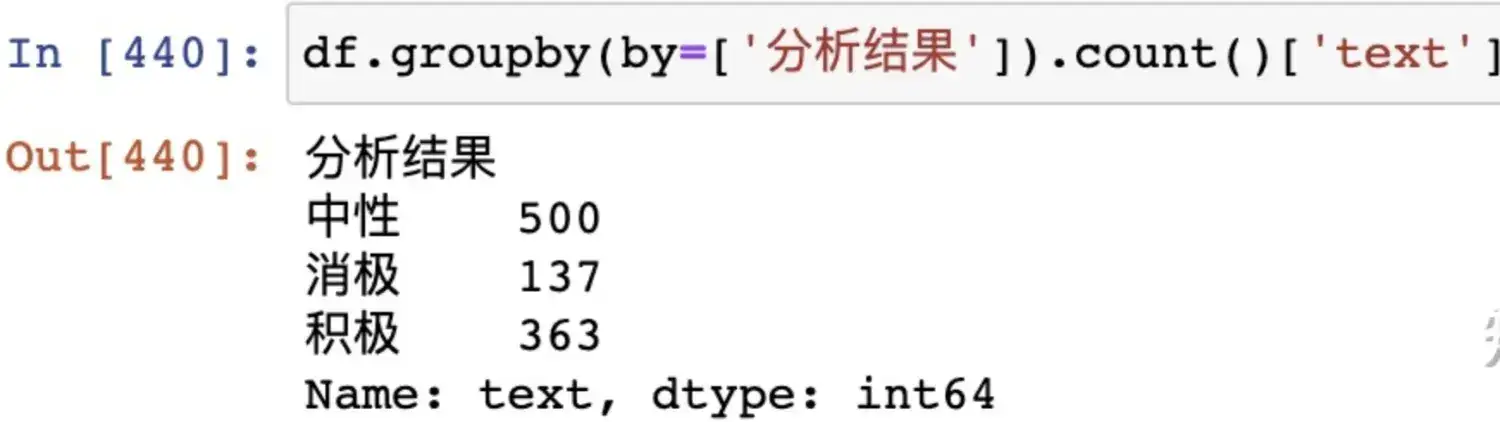
Hashbrown:深入探索哈希表中的两次查询奥秘
在现代编程领域,哈希表(又称散列表)凭借其卓越的查询性能和广泛的应用场景,成为构建复杂应用程序不可或缺的数据结构。Rust 编程语言中的 Hashbrown 库,以其出色的性能和简洁的设计而备受推崇,在哈希表实现中独树一帜。
哈希表的原理与运作机制
哈希表是一种基于哈希函数的数据结构,它将键值映射到一个哈希值,并利用哈希值快速查找和存储对应的数据。如同字典,哈希函数将键值转换成哈希表的特定位置,实现数据的快速检索。
然而,哈希函数的潜在缺陷在于碰撞,即不同的键值可能映射到相同的哈希值。为了解决这一问题,哈希表通常采用链表或其他数据结构来存储具有相同哈希值的元素,避免数据丢失。
Hashbrown 的两次查询
传统的哈希表通常进行一次查询来查找元素,直接根据键值计算哈希值,然后在哈希表中检索相应元素。而 Hashbrown 却打破这一常规,采用独特的两次查询机制。
第一次查询与传统哈希表类似,根据键值计算哈希值,然后在哈希表中查找元素。但如果第一次查询失败,Hashbrown 不会立即停止,而是进行第二次查询。第二次查询将对键值进行额外的处理,如转换字符串为哈希值,然后再次在哈希表中查找元素。
两次查询的奥秘
Hashbrown 采用两次查询机制,主要基于以下原因:
1. 提高查询性能
在某些情况下,第二次查询可以帮助 Hashbrown 更快地找到元素。例如,当键值是字符串时,Hashbrown 会将字符串转换为哈希值进行第一次查询。如果第一次查询没有找到元素,第二次查询则会将字符串转换为另一个哈希值,从而有可能更快地找到元素。
2. 减少哈希冲突
通过两次查询,Hashbrown 可以有效地减少哈希冲突。第一次查询使用一种哈希函数,第二次查询使用另一种哈希函数,这降低了不同键值映射到相同哈希值的机会,从而提高了哈希表的整体性能。
3. 提高内存利用率
Hashbrown 的两次查询机制可以提高内存利用率。第一次查询失败后,第二次查询可能会找到一个空闲的哈希桶,然后将元素存储在其中。这有助于避免哈希表的过度拥挤,从而提高内存利用率。
代码示例
// 使用 Hashbrown 创建哈希表
use hashbrown::HashMap;
// 创建一个 HashMap
let mut my_hashmap = HashMap::new();
// 插入键值对
my_hashmap.insert("key1", "value1");
my_hashmap.insert("key2", "value2");
// 使用第一次查询查找元素
match my_hashmap.get("key1") {
Some(value) => println!("Found value: {}", value),
None => println!("Key not found"),
}
// 使用第二次查询查找元素
match my_hashmap.get("key3") {
Some(value) => println!("Found value: {}", value),
None => println!("Key not found"),
}
常见问题解答
1. 为什么 Hashbrown 要进行两次查询?
Hashbrown 采用两次查询机制来提高查询性能、减少哈希冲突和提高内存利用率。
2. Hashbrown 使用什么哈希函数?
Hashbrown 使用 MurmurHash3 哈希函数进行第一次查询,并根据键值类型动态选择不同的哈希函数进行第二次查询。
3. Hashbrown 的两次查询会影响性能吗?
在大多数情况下,Hashbrown 的两次查询不会显着影响性能。然而,在键值非常相似或键值是自定义类型时,第二次查询可能会导致性能下降。
4. Hashbrown 适合哪些场景?
Hashbrown 适用于需要快速查找和存储大量键值对的场景,如缓存、数据库索引和网络协议。
5. 与其他哈希表实现相比,Hashbrown 有什么优势?
Hashbrown 具有卓越的性能、简洁的设计、广泛的文档和社区支持,使其成为 Rust 编程语言中哈希表的首选实现。
结语
Hashbrown 的两次查询机制是其设计中的巧妙之处,它通过这种方式在性能、冲突处理和内存利用率方面做到了平衡。Hashbrown 的出色表现也证明了这种设计思路的成功。它不仅成为了 Rust 编程语言的标准库中的重要组成部分,也成为了众多开发者的首选哈希表实现。