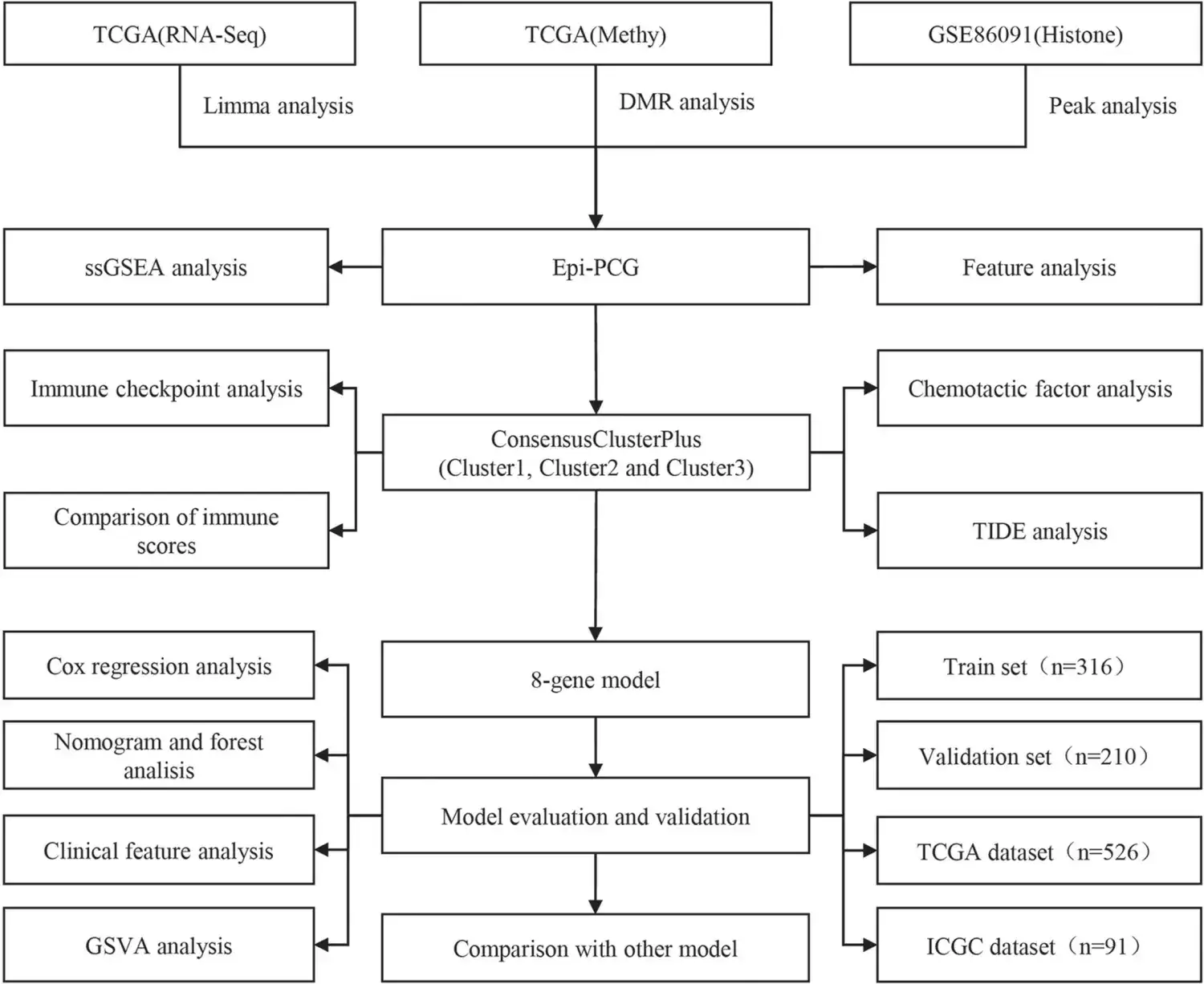
EfficientNetV2:更强更快更小的图像分类模型
2024-01-03 01:16:18
引言
在当今人工智能时代,计算机视觉已成为不可或缺的一部分,图像分类是其中一项基本任务。EfficientNetV2 应运而生,成为图像分类领域的最新突破,以其更快的训练速度、更小的模型体积和卓越的性能令人惊叹。
EfficientNetV2 的优势
EfficientNetV2 与其前身相比具有多项优势:
- 训练速度更快: EfficientNetV2 采用新型复合缩放方法,可显着缩短训练时间。
- 模型体积更小: 通过优化网络架构,EfficientNetV2 的参数数量和模型大小大幅减少。
- 性能更强: 尽管体积更小,但 EfficientNetV2 在 ImageNet 数据集上的准确率却大幅提高。
复合缩放方法
EfficientNetV2 的复合缩放方法是其性能提升的关键。该方法结合了深度、宽度和分辨率缩放,从而创建了更有效率的网络架构。深度缩放通过增加网络层数来提升性能,而宽度缩放通过增加每个层中的通道数来增强表示能力。分辨率缩放则通过提高输入图像的分辨率来改进模型的精细度。
优化网络架构
除了复合缩放方法,EfficientNetV2 还对网络架构进行了优化。这些优化包括:
- MBConvV2 卷积: EfficientNetV2 使用经过优化的 MBConvV2 卷积,在保持性能的同时减少了计算量。
- Swish 激活函数: Swish 激活函数替代了 ReLU 激活函数,进一步提升了模型的性能。
- SE 模块: SE 模块被添加到网络中,以增强通道间的交互。
实验结果
在 ImageNet 数据集上的广泛实验表明,EfficientNetV2 的表现优于其前身和其他最先进的模型。对于不同的输入分辨率,EfficientNetV2 都取得了更高的准确率。
应用
EfficientNetV2 的高效性和性能使其适用于广泛的图像分类应用,包括:
- 目标检测
- 图像分割
- 人脸识别
- 医疗诊断
总结
EfficientNetV2 是图像分类领域的重大进步。它结合了复合缩放方法、网络架构优化和先进技术,实现了更快的训练速度、更小的模型体积和更高的性能。随着计算机视觉应用的不断发展,EfficientNetV2 将继续成为该领域的关键推动因素。
参考文献
[1] Tan, M., & Le, Q. V. (2019). EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv preprint arXiv:1905.11946.
[2] Tan, M., & Le, Q. V. (2021). EfficientNetV2: Smaller Models and Faster Training. arXiv preprint arXiv:2104.00298.