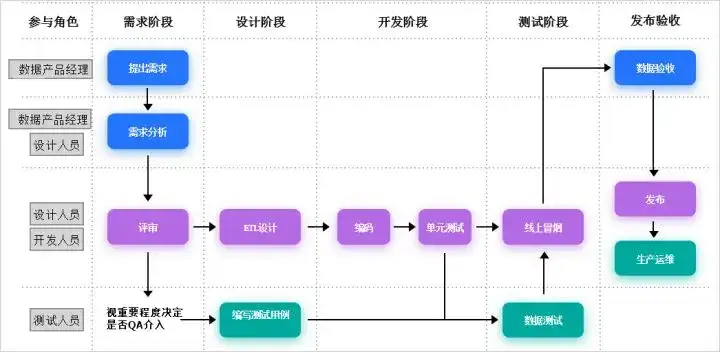
返回
释放数据潜力:Hive 实用函数指南
见解分享
2023-12-26 22:24:38
**Hive 实用函数指南:释放数据处理潜能**
作为大数据处理领域的先驱,Hive 凭借其将 SQL 语言与 Hadoop 生态系统相结合的能力而备受推崇。它通过提供一系列实用函数,使数据分析人员能够对大量分布式数据执行复杂的查询。从字符串操作到统计聚合,掌握这些函数是优化性能和提取有价值见解的关键。
**1. 字符串函数**
* **concat():** 连接多个字符串。
* **substr():** 截取字符串的子字符串。
* **replace():** 替换字符串中的子字符串。
* **instr():** 查找子字符串在字符串中首次出现的索引。
* **lcase():** 将字符串转换为小写。
**2. 日期和时间函数**
* **from_unixtime():** 将 Unix 时间戳转换为日期时间字符串。
* **to_date():** 将字符串转换为日期时间格式。
* **add_months():** 在指定日期时间中添加指定月数。
* **date_format():** 根据指定格式格式化日期时间。
**3. 数学函数**
* **abs():** 取绝对值。
* **round():** 四舍五入到指定小数位。
* **ceil():** 向上取整到最接近的整数。
* **floor():** 向下取整到最接近的整数。
* **log():** 计算对数。
**4. 统计函数**
* **avg():** 计算平均值。
* **count():** 计算行数。
* **max():** 获取最大值。
* **min():** 获取最小值。
* **sum():** 计算总和。
**5. 条件函数**
* **if():** 根据条件返回不同值。
* **case():** 根据一组条件执行一系列操作。
* **coalesce():** 返回第一个非空值。
* **nullif():** 如果两个值相等,则返回 null。
**性能优化技巧**
为了优化 Hive 查询性能,可以考虑以下技巧:
* **使用分区和桶:** 将数据划分为较小的块,从而减少扫描的数据量。
* **选择正确的存储格式:** 针对您的特定查询模式选择合适的存储格式,如 ORC 或 Parquet。
* **利用矢量化执行:** 使用支持 SIMD 指令的函数,以提升处理效率。
* **避免不必要的 JOIN:** 只在绝对必要时执行 JOIN 操作,并使用适当的优化策略。
**结语**
通过掌握 Hive 实用函数,您可以充分发挥 Hive 的强大功能,高效处理海量数据并提取有价值的见解。无论您是数据分析师还是数据工程师,这些函数都是优化查询、提升性能和释放数据潜力的宝贵工具。随着大数据领域的发展,Hive 将继续作为不可或缺的分析平台,而熟练掌握其实用函数将帮助您在竞争激烈的环境中脱颖而出。