走进Kaggle的世界:揭秘十大学习技巧,打造先进的深度学习算法
2024-01-06 21:24:22
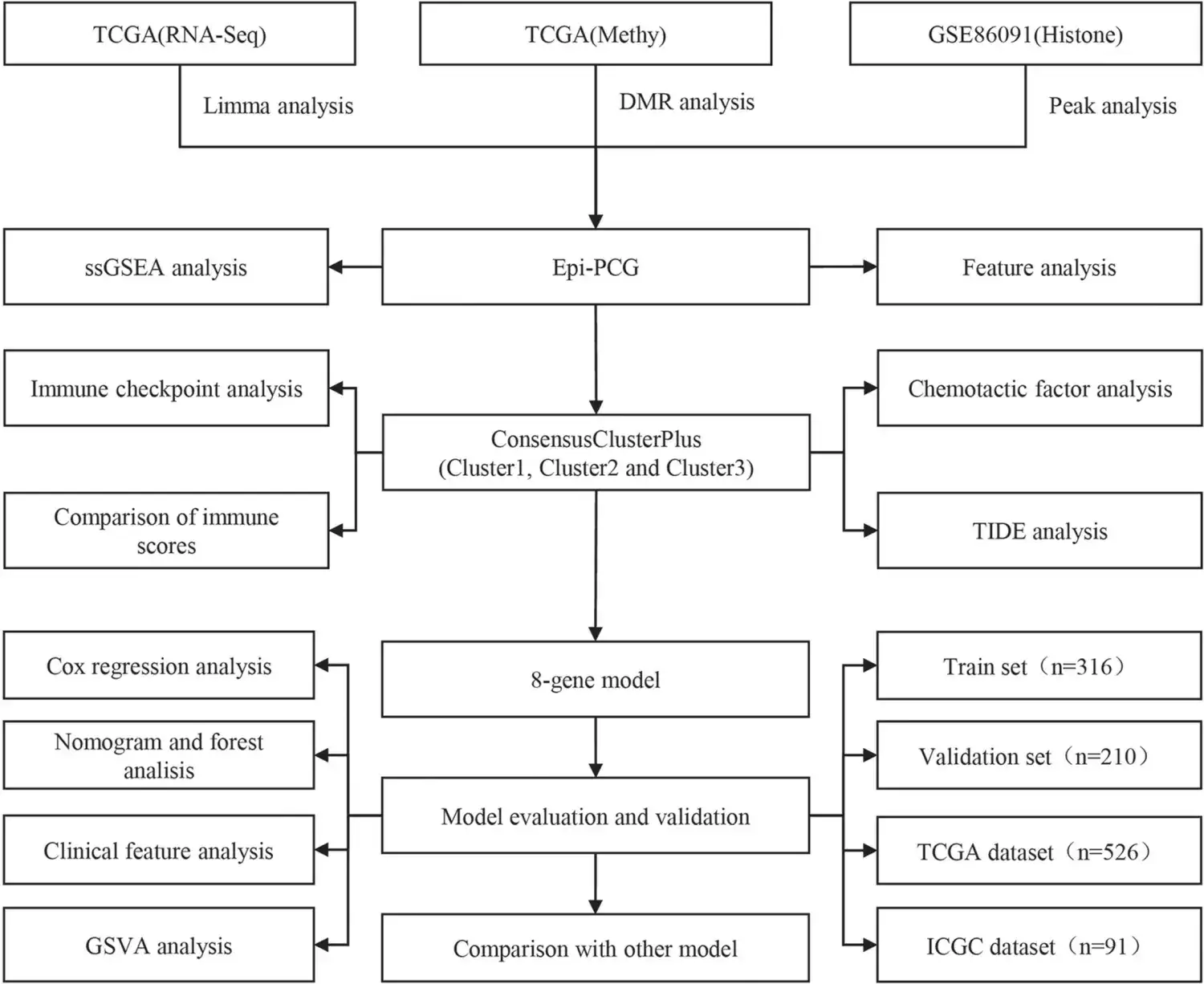
踏入 Kaggle 巅峰的十大神器
在数据科学和机器学习浩瀚的领域中,Kaggle 犹如一座拔地而起的奥林匹克舞台,吸引了来自世界各地的顶尖人才齐聚一堂。踏入 Kaggle 的世界,意味着踏上了一个充满挑战与机遇的征程。为了助您在这条道路上披荆斩棘,直指 Kaggle 巅峰,以下十大神器必不可少。
一、数据预处理:筑基石上的数据炼金
数据预处理好比为建造摩天大厦打下坚实的地基。它涉及一系列操作,包括数据清洗、缺失值处理、归一化等,这些步骤至关重要,能确保您从原始数据中提取出有用且有意义的信息。
二、模型选择:因材施教的算法大观园
选择合适的模型如同为特定任务挑选最趁手的工具。Kaggle 上提供了各种模型,包括随机森林、支持向量机、神经网络等,了解不同模型的优缺点,并根据数据的特征和任务要求合理选择,将为您的成功奠定坚实基础。
三、调参优化:精益求精的数据雕刻艺术
调参优化是将模型性能提升到极致的秘诀。通过调整模型的超参数,例如学习率、正则化系数等,您可以微调模型的行为,使其更契合数据分布,从而获得更优的预测结果。
四、数据增强:变幻莫测的数据镜像
数据增强是一种巧妙的技术,可以增加训练数据集的大小和多样性。通过对数据进行诸如旋转、翻转、裁剪等变换,模型能够从更多角度学习数据,从而提高泛化能力,降低过拟合风险。
五、交叉验证:防止过拟合的试金石
交叉验证是避免模型过度拟合的利器。它将数据集划分为训练集和测试集,多次训练模型,并以不同的方式划分数据集,通过比较不同划分方式下的模型性能,可以客观评估模型的泛化能力。
六、集成学习:众智聚力的模型联盟
集成学习是一种将多个模型结合起来进行预测的强大技术。通过将不同模型的预测结果进行加权平均或投票等方式,集成学习可以降低单一模型的偏差,提高预测的准确性。
七、特征工程:数据中的隐藏宝藏
特征工程是挖掘数据中隐藏价值的必备技能。通过衍生新的特征、选择最具信息量的特征等操作,您可以创建更具表征力的数据表示,帮助模型更好地理解和预测目标变量。
八、可视化分析:数据的鲜活绘卷
可视化分析是将复杂的数据转化为直观图表的艺术。通过热力图、散点图、柱状图等可视化方式,您可以发现数据中的模式、趋势和异常值,从而深入理解数据,辅助模型训练和决策。
九、代码简洁:逻辑的优雅舞步
简洁清晰的代码是数据科学工作流中的瑰宝。它不仅提高了可读性和可维护性,还能避免错误的发生。遵循最佳实践,例如模块化设计、适当的注释和文档,可以确保您的代码经得起时间的考验。
十、不断学习:知识的永续航行
在 Kaggle 的世界里,学习永无止境。从书籍到博客,从视频到研讨会,丰富的学习资源触手可及。不断学习、探索新的技术和算法,将让您始终立于时代前沿,在 Kaggle 的竞赛中脱颖而出。
解锁 Kaggle 之门
装备了这十大神器,您已经具备了踏入 Kaggle 世界所需的必备技能。现在,是时候打开 Kaggle 的大门,开始一段充满挑战与机遇的精彩旅程。在 Kaggle 的舞台上,您将与世界各地的顶尖人才一较高下,磨炼自己的技术,解锁无限可能。
常见问题解答
Q1:我该如何选择最适合我的模型?
A1:模型选择取决于任务类型、数据特性和计算资源的可用性。尝试不同的模型,并通过交叉验证比较它们的性能。
Q2:调参优化是否需要花费大量时间?
A2:调参优化需要时间,但可以显著提升模型性能。使用网格搜索或贝叶斯优化等自动化方法可以简化流程。
Q3:特征工程是否比模型选择更重要?
A3:特征工程和模型选择同样重要。高质量的特征可以帮助模型更好地学习数据,而适当的模型可以充分利用这些特征进行预测。
Q4:可视化分析在 Kaggle 中扮演什么角色?
A4:可视化分析有助于理解数据、识别异常值和指导模型开发。它可以帮助您从不同的角度审视数据,发现潜在的模式和趋势。
Q5:如何在 Kaggle 中脱颖而出?
A5:在 Kaggle 中脱颖而出需要扎实的技术技能、创造性的思维和不断的学习。积极参与竞赛、分享您的见解和向社区学习,将有助于您在 Kaggle 之路上取得成功。
代码示例:
# 数据预处理示例
import pandas as pd
data = pd.read_csv('data.csv')
data = data.dropna()
data = data.normalize()
# 模型选择示例
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeClassifier
model = LinearRegression()
model = DecisionTreeClassifier()
# 调参优化示例
from sklearn.model_selection import GridSearchCV
params = {'learning_rate': [0.01, 0.05, 0.1], 'max_depth': [3, 5, 7]}
grid_search = GridSearchCV(model, params, cv=5)
grid_search.fit(X, y)