释放 GPU 潜能:揭秘 CPU 高效工作委派的秘诀
2023-04-19 16:11:17
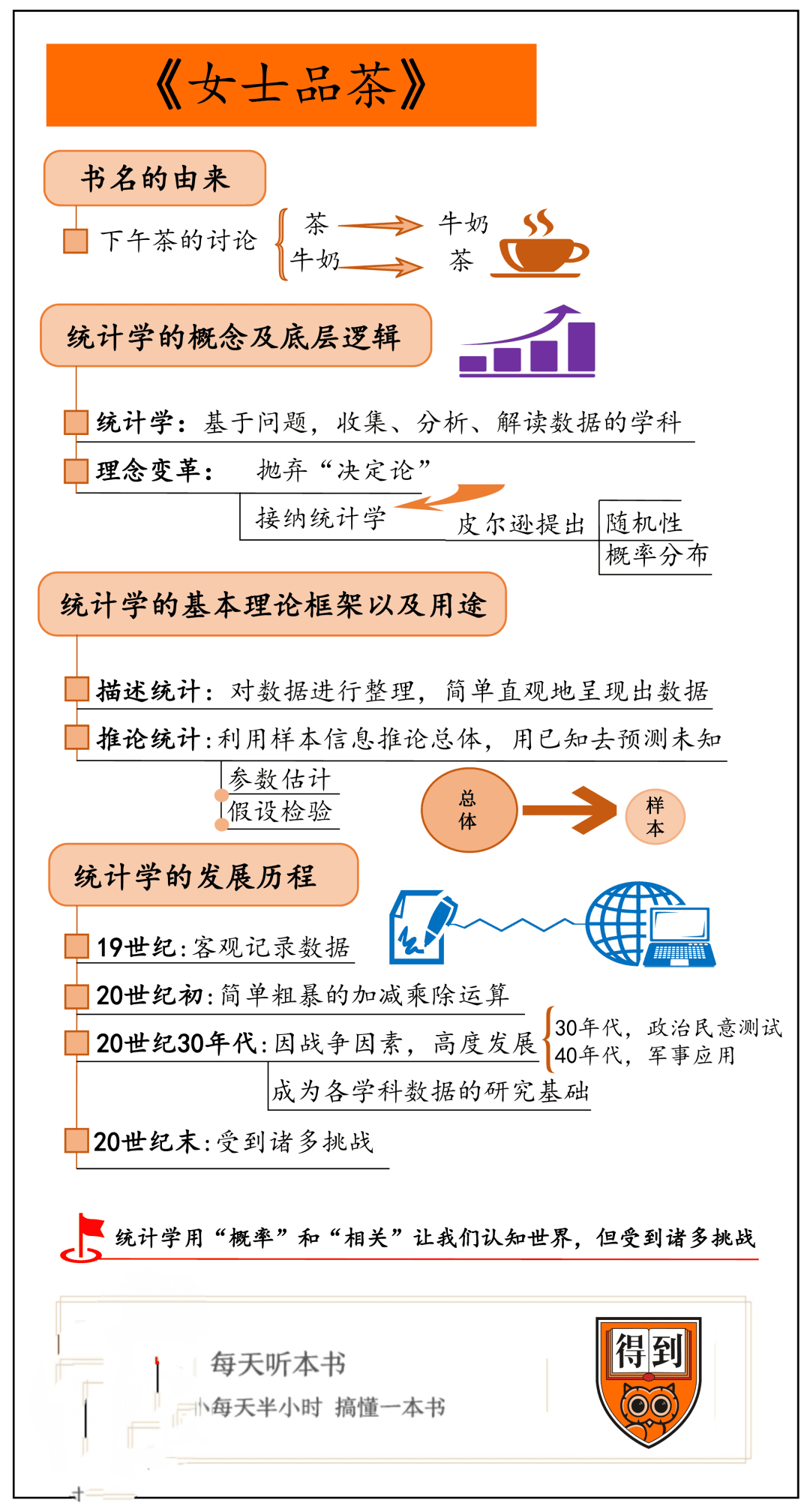
CPU 和 GPU 的协同作战:释放性能潜能的关键
高效的工作委派:优化应用程序性能
充分利用 NVIDIA GPU 的强大性能的关键在于高效的工作委派。当 CPU 过载,无法处理大量任务时,GPU 的性能也会受限,导致应用程序运行不畅。以下是一些行之有效的技巧,助你改善 CPU 工作委派,释放 GPU 的全部潜能:
-
避免不必要的任务委派: 不要将本来可以由 CPU 轻松处理的任务交给 GPU。这只会增加 GPU 的负担,使其性能下降。
-
合理分配任务: 根据 CPU 和 GPU 的各自优势合理分配任务。例如,将图形渲染和计算密集型任务交给 GPU,而将逻辑和控制任务交给 CPU。
-
减少数据传输开销: 在 CPU 和 GPU 之间传输数据时,务必注意减少开销。使用高效的数据传输方法,如 DMA 或共享内存,以避免不必要的延迟和性能损失。
-
优化并行处理: 充分利用 CPU 和 GPU 的并行处理能力。将任务分解成多个子任务,并行执行,以提高整体性能。
-
使用合适的编程语言和工具: 选择合适的编程语言和工具,可以显著影响应用程序的性能。使用支持高效并行编程的语言,如 C++ 或 CUDA,并使用适当的库和工具,以充分发挥 CPU 和 GPU 的潜力。
代码示例:
// 使用 CUDA 优化并行处理
__global__ void myKernel(int* data, int size) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < size) {
data[idx] = data[idx] * 2;
}
}
平衡 CPU 和 GPU:提升应用程序性能的黄金法则
在优化应用程序性能时,平衡 CPU 和 GPU 的负载至关重要。如果 CPU 过载,GPU 就会闲置,导致性能浪费。反之亦然。通过精心设计应用程序的架构和算法,合理分配任务,确保 CPU 和 GPU 都能充分发挥其作用,才能获得最佳的性能表现。
代码示例:
# 使用多线程优化 CPU 处理
import threading
import time
def cpu_task(data):
for i in range(len(data)):
data[i] = data[i] + 1
def main():
data = [1, 2, 3, 4, 5]
threads = []
# 创建多个线程来并行执行 CPU 任务
for i in range(4):
thread = threading.Thread(target=cpu_task, args=(data,))
threads.append(thread)
# 启动所有线程
for thread in threads:
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
# 主线程继续执行
print(data) # 输出:[2, 3, 4, 5, 6]
if __name__ == "__main__":
main()
结论:拥抱高效工作委派,释放 GPU 潜能
高效的工作委派是充分利用 NVIDIA GPU 性能的关键。通过合理分配任务、减少数据传输开销、优化并行处理、选择合适的编程语言和工具,以及平衡 CPU 和 GPU 的负载,你可以显著提升应用程序的性能,享受流畅的视觉体验和无缝的操作体验。拥抱高效工作委派,释放 GPU 的潜能,让你的应用程序飞驰而行!
常见问题解答
-
如何判断 CPU 是否成为应用程序性能的瓶颈?
通过监视 CPU 使用率和应用程序性能指标,可以判断 CPU 是否成为瓶颈。如果 CPU 使用率持续高,而应用程序性能不佳,则可能是 CPU 成为瓶颈。
-
如何优化 CPU 和 GPU 之间的数据传输?
使用高效的数据传输方法,如 DMA 或共享内存,以减少数据传输开销。此外,可以考虑使用数据压缩技术来进一步减少数据传输量。
-
并行处理的最佳实践是什么?
充分分解任务以创建大量可并行执行的小任务。使用合适的并行编程模型和库,并根据硬件架构调整并行度。
-
如何选择合适的编程语言和工具来优化 CPU 和 GPU 性能?
选择支持高效并行编程的语言,如 C++ 或 CUDA。使用适当的库和工具,如 NVIDIA CUDA Toolkit,以充分利用 GPU 的功能。
-
如何确保 CPU 和 GPU 之间的负载平衡?
通过仔细分析应用程序的行为和资源使用情况,合理分配任务,以确保 CPU 和 GPU 的负载平衡。使用性能分析工具来监控和调整应用程序的性能。